In a recent previous post, I gave a method that I have used to create test data. As I was playing with the new anonymize() function introduced in SQL Server 2016 RC0, it occurred to me that it could be used for similar purpose.
The Books Online page for anonymize() is somewhat skimpy as of this writing, but there’s enough to figure out a the general idea. The function always require a column as input, and this seems to be the case so that the function can sample the data in the column to determine the range of output values, particularly with numeric data types. However, with fewer than three rows, there just doesn’t seem to be enough to work with, and anonymize() will simply output the row values.
declare @t table (FirstName nvarchar(25), LastName nvarchar(25), Age int, DateOfBirth date);
insert @t (FirstName, LastName, Age, DateOfBirth)
values ('Mark', 'Smith', 25, '1990-09-01'),
('Emily', 'Jones', 23, '1992-12-31');
select anonymize(FirstName) as FirstName,
anonymize(LastName) as LastName,
anonymize(Age) as Age,
anonymize(DateOfBirth) as DateOfBirth
from @t; |
declare @t table (FirstName nvarchar(25), LastName nvarchar(25), Age int, DateOfBirth date);
insert @t (FirstName, LastName, Age, DateOfBirth)
values ('Mark', 'Smith', 25, '1990-09-01'),
('Emily', 'Jones', 23, '1992-12-31');
select anonymize(FirstName) as FirstName,
anonymize(LastName) as LastName,
anonymize(Age) as Age,
anonymize(DateOfBirth) as DateOfBirth
from @t;

But when we add a third row, the magic starts to happen. I’ll run this statement twice in a row:
declare @t table (FirstName nvarchar(25), LastName nvarchar(25), Age int, DateOfBirth date);
insert @t (FirstName, LastName, Age, DateOfBirth)
values ('Mark', 'Smith', 25, '1990-09-01'),
('Emily', 'Jones', 23, '1992-12-31'),
('Sara', 'Brown', 31, '1985-02-22');
select anonymize(FirstName) as FirstName,
anonymize(LastName),
anonymize(Age) as Age,
anonymize(DateOfBirth) as DateOfBirth
from @t; |
declare @t table (FirstName nvarchar(25), LastName nvarchar(25), Age int, DateOfBirth date);
insert @t (FirstName, LastName, Age, DateOfBirth)
values ('Mark', 'Smith', 25, '1990-09-01'),
('Emily', 'Jones', 23, '1992-12-31'),
('Sara', 'Brown', 31, '1985-02-22');
select anonymize(FirstName) as FirstName,
anonymize(LastName),
anonymize(Age) as Age,
anonymize(DateOfBirth) as DateOfBirth
from @t;
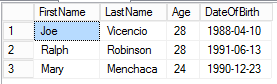
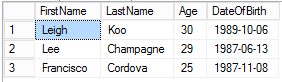
So, a couple of observations. First, the ages that are displayed are in the range of the input data. That is, the input in the age column are between 23 and 31 years old, and the output are similarly from 24 to 28 in the first result, and from 25 to 30 in the second. Clearly, SQL Server is reading the input column and basing the anonymized output on the data in there. Similarly, the dates output are in the ranges of the input column. However, there is no relationship between Age and DateOfBirth, which makes sense since SQL Server has nothing to tie the two columns together. (Books Online makes it clear, by the way, that anonymize() will not work on computed columns.)
But the real magic happens with the names columns (both first and last). Notice that the function output values are in no way derived from the inputs. I have to admit to being quite impressed that with only three rows, SQL Server can interpret that these columns contain name data. And no, it not based on the column names; when I rename the columns to c1 and c2, the above example still works fine.
Perhaps more impressive is that it can detect and generate addresses as well, even using obviously fake address data as input.
declare @t table (Address nvarchar(100), City nvarchar(40), State nvarchar(5));
insert @t (Address, City, State)
values ('1234 Main St', 'Anytown', 'PA'),
('987 E 1st Ave', 'Podunkville', 'KS'),
('456 S 654 W', 'By the Sea', 'CA');
select anonymize(Address),
anonymize(City),
anonymize(State)
from @t; |
declare @t table (Address nvarchar(100), City nvarchar(40), State nvarchar(5));
insert @t (Address, City, State)
values ('1234 Main St', 'Anytown', 'PA'),
('987 E 1st Ave', 'Podunkville', 'KS'),
('456 S 654 W', 'By the Sea', 'CA');
select anonymize(Address),
anonymize(City),
anonymize(State)
from @t;

As with many other new features, the anonymize() function comes with a host of limitations. As previously mentioned, it doesn’t work on computed columns. As you would expect, you cannot use it in a WHERE clause, and the function is incompatible with most other new SQL Server features, including Always Encrypted, in-memory tables and temporal tables. Interesting things also happen when you use anonymize() with a TOP clause.
declare @t table (FirstName nvarchar(25), LastName nvarchar(25), Age int, DateOfBirth date);
insert @t (FirstName, LastName, Age, DateOfBirth)
values ('Mark', 'Smith', 25, '1990-09-01'),
('Emily', 'Jones', 23, '1992-12-31'),
('Sara', 'Brown', 31, '1985-02-22');
select top 1 anonymize(FirstName) as FirstName,
anonymize(LastName) as LastName,
anonymize(DateOfBirth) as DateOfBirth |
declare @t table (FirstName nvarchar(25), LastName nvarchar(25), Age int, DateOfBirth date);
insert @t (FirstName, LastName, Age, DateOfBirth)
values ('Mark', 'Smith', 25, '1990-09-01'),
('Emily', 'Jones', 23, '1992-12-31'),
('Sara', 'Brown', 31, '1985-02-22');
select top 1 anonymize(FirstName) as FirstName,
anonymize(LastName) as LastName,
anonymize(DateOfBirth) as DateOfBirth
