I have occasionally had to convert from local time to UTC in SQL Server, but unfortunately there is no built-in functionality to do this. I will share one solution in this post to accomplish this conversion.
By far, the hardest part of the conversion has been accounting for daylight saving time. The rules behind DST vary greatly in different parts of the world and change periodically. The solution that I present here works only for the United States, as accounting for every possible combination would be far more complex. Even for the United States, this code doesn’t account for everything; however, for my purposes, this has been more than adequate.
A little research shows that in the United States, there was no uniform DST rule prior to 1966, and I am making the simplification to ignore DST from 1965 and earlier. One set of rules applied from 1966 to 1986 (last Sunday in April to last Sunday in October). There were some exceptions in 1974 and 1975, but I am ignoring that here. From 1987 to 2006, DST was in effect from the first Sunday in April to the last Sunday in October, and since 2007 it is in effect from the second Sunday in March until the first Sunday in November. The change always happens at 2:00 am local time.
In order to implement this code, I first create a small code table that tells us when when DST starts and ends. This table, as well as all of the functions described in this post, should be created in an administrative database. The table structure is:
create table DstRanges
(
RangeID int not null identity(1,1) primary key clustered,
RangeStart datetime null,
RangeEnd datetime null,
IsDst bit not null
);
create nonclustered index ix_DstRanges__RangeStart_RangeEnd on DstRanges (RangeStart, RangeEnd);
go |
create table DstRanges
(
RangeID int not null identity(1,1) primary key clustered,
RangeStart datetime null,
RangeEnd datetime null,
IsDst bit not null
);
create nonclustered index ix_DstRanges__RangeStart_RangeEnd on DstRanges (RangeStart, RangeEnd);
go
Next, I create a helper function that will be used to populate the DstRanges tables. This function can dropped after the load is completed.
create function fn_GetDSTBeginEnd (@date datetime)
returns @dates table (dst_begin datetime, dst_end datetime)
as
begin
declare @year int,
@dst_begin datetime,
@dst_end datetime;
-- determine if daylight saving time is in effect (all of the following rules based in the US)
select @year = datepart(year, @date);
-- From 1966 to 1986, daylight saving in effect from:
-- last Sunday in April until the last Sunday in October
-- (some exception for 1974-1975, but those will not be accounted for here)
if @year >= 1966 and @year <= 1986
begin
-- start by getting May 1 and November 1
select @dst_begin = cast(cast(@year as varchar(20)) + '-05-01' as datetime),
@dst_end = cast(cast(@year as varchar(20)) + '-11-01' as datetime);
-- set to first Sunday in May and first Sunday in November
select @dst_begin = dateadd(day, 7 - ((datepart(weekday, @dst_begin) + @@datefirst - 1) % 7), @dst_begin),
@dst_end = dateadd(day, 7 - ((datepart(weekday, @dst_end) + @@datefirst - 1) % 7), @dst_end);
-- back one week to get last Sunday in April and last Sunday in October
select @dst_begin = dateadd(day, -7, @dst_begin),
@dst_end = dateadd(day, -7, @dst_end);
-- add two hours because the clock change happens at 2:00 am
select @dst_begin = dateadd(hour, 2, @dst_begin),
@dst_end = dateadd(hour, 2, @dst_end);
end;
-- From 1987 to 2006, daylight saving in effect from:
-- first Sunday in April until the last Sunday in October
else if @year >= 1987 and @year <= 2006
begin
-- start by getting April 1 and November 1
select @dst_begin = cast(cast(@year as varchar(20)) + '-04-01' as datetime),
@dst_end = cast(cast(@year as varchar(20)) + '-11-01' as datetime);
-- set to first Sunday in April and first Sunday in November
select @dst_begin = dateadd(day, 7 - ((datepart(weekday, @dst_begin) + @@datefirst - 1) % 7), @dst_begin),
@dst_end = dateadd(day, 7 - ((datepart(weekday, @dst_end) + @@datefirst - 1) % 7), @dst_end);
-- back off end date by one week to get last Sunday in October
select @dst_end = dateadd(day, -7, @dst_end);
-- add two hours because the clock change happens at 2:00 am
select @dst_begin = dateadd(hour, 2, @dst_begin),
@dst_end = dateadd(hour, 2, @dst_end);
end;
-- From 2007 onward, daylight saving in effect from:
-- second Sunday in March until the first Sunday in November
else if @year >= 2007
begin
-- start by getting March 1 and November 1
select @dst_begin = cast(cast(@year as varchar(20)) + '-03-01' as datetime),
@dst_end = cast(cast(@year as varchar(20)) + '-11-01' as datetime);
-- set to first Sunday in March and first Sunday in November
select @dst_begin = dateadd(day, (7 - ((datepart(weekday, @dst_begin) + @@datefirst - 1) % 7))%7, @dst_begin),
@dst_end = dateadd(day, (7 - ((datepart(weekday, @dst_end) + @@datefirst - 1) % 7))%7, @dst_end);
-- forward end date by one week to get second Sunday in March
select @dst_begin = dateadd(day, 7, @dst_begin);
-- add two hours because the clock change happens at 2:00 am
select @dst_begin = dateadd(hour, 2, @dst_begin),
@dst_end = dateadd(hour, 2, @dst_end);
end;
if @date >= @dst_begin
and @date < @dst_end
begin
-- spring forward
select @date = dateadd(hour, 1, @date);
end;
insert @dates (dst_begin, dst_end) values (@dst_begin, @dst_end);
return;
end
go |
create function fn_GetDSTBeginEnd (@date datetime)
returns @dates table (dst_begin datetime, dst_end datetime)
as
begin
declare @year int,
@dst_begin datetime,
@dst_end datetime;
-- determine if daylight saving time is in effect (all of the following rules based in the US)
select @year = datepart(year, @date);
-- From 1966 to 1986, daylight saving in effect from:
-- last Sunday in April until the last Sunday in October
-- (some exception for 1974-1975, but those will not be accounted for here)
if @year >= 1966 and @year <= 1986
begin
-- start by getting May 1 and November 1
select @dst_begin = cast(cast(@year as varchar(20)) + '-05-01' as datetime),
@dst_end = cast(cast(@year as varchar(20)) + '-11-01' as datetime);
-- set to first Sunday in May and first Sunday in November
select @dst_begin = dateadd(day, 7 - ((datepart(weekday, @dst_begin) + @@datefirst - 1) % 7), @dst_begin),
@dst_end = dateadd(day, 7 - ((datepart(weekday, @dst_end) + @@datefirst - 1) % 7), @dst_end);
-- back one week to get last Sunday in April and last Sunday in October
select @dst_begin = dateadd(day, -7, @dst_begin),
@dst_end = dateadd(day, -7, @dst_end);
-- add two hours because the clock change happens at 2:00 am
select @dst_begin = dateadd(hour, 2, @dst_begin),
@dst_end = dateadd(hour, 2, @dst_end);
end;
-- From 1987 to 2006, daylight saving in effect from:
-- first Sunday in April until the last Sunday in October
else if @year >= 1987 and @year <= 2006
begin
-- start by getting April 1 and November 1
select @dst_begin = cast(cast(@year as varchar(20)) + '-04-01' as datetime),
@dst_end = cast(cast(@year as varchar(20)) + '-11-01' as datetime);
-- set to first Sunday in April and first Sunday in November
select @dst_begin = dateadd(day, 7 - ((datepart(weekday, @dst_begin) + @@datefirst - 1) % 7), @dst_begin),
@dst_end = dateadd(day, 7 - ((datepart(weekday, @dst_end) + @@datefirst - 1) % 7), @dst_end);
-- back off end date by one week to get last Sunday in October
select @dst_end = dateadd(day, -7, @dst_end);
-- add two hours because the clock change happens at 2:00 am
select @dst_begin = dateadd(hour, 2, @dst_begin),
@dst_end = dateadd(hour, 2, @dst_end);
end;
-- From 2007 onward, daylight saving in effect from:
-- second Sunday in March until the first Sunday in November
else if @year >= 2007
begin
-- start by getting March 1 and November 1
select @dst_begin = cast(cast(@year as varchar(20)) + '-03-01' as datetime),
@dst_end = cast(cast(@year as varchar(20)) + '-11-01' as datetime);
-- set to first Sunday in March and first Sunday in November
select @dst_begin = dateadd(day, (7 - ((datepart(weekday, @dst_begin) + @@datefirst - 1) % 7))%7, @dst_begin),
@dst_end = dateadd(day, (7 - ((datepart(weekday, @dst_end) + @@datefirst - 1) % 7))%7, @dst_end);
-- forward end date by one week to get second Sunday in March
select @dst_begin = dateadd(day, 7, @dst_begin);
-- add two hours because the clock change happens at 2:00 am
select @dst_begin = dateadd(hour, 2, @dst_begin),
@dst_end = dateadd(hour, 2, @dst_end);
end;
if @date >= @dst_begin
and @date < @dst_end
begin
-- spring forward
select @date = dateadd(hour, 1, @date);
end;
insert @dates (dst_begin, dst_end) values (@dst_begin, @dst_end);
return;
end
go
And next, the table can be populated with this code. In this example the table will be loaded through the year 2099, assuming that the current rules are not changed.
create table #year
(
YearNbr int not null,
DstStart datetime null,
DstEnd datetime null
);
with l0 as (select 1 v union all select 1), l1 as (select a.v from l0 a, l0), l2 as (select a.v from l1 a, l1),
l3 as (select a.v from l2 a, l2), l4 as (select a.v from l3 a, l3), l5 as (select a.v from l4 a, l4),
nums as (select row_number() over (order by (select null)) n from l5)
insert #year (YearNbr)
select n.n
from nums n
where n.n >= 1966
and n.n <= 2099;
update y
set y.DstStart = dst.dst_begin,
y.DstEnd = dst.dst_end
from #year y cross apply (select * from fn_GetDSTBeginEnd(datefromparts(y.YearNbr, 1, 1))) dst;
with Dst as
(
select y.YearNbr,
lag(y.DstEnd, 1, null) over (order by y.YearNbr) PrevDstEnd,
y.DstStart,
y.DstEnd
from #year y
)
insert DstRanges (RangeStart, RangeEnd, IsDst)
select Dst.PrevDstEnd RangeStart, DstStart RangeEnd, 0
from Dst
union all
select DstStart RangeStart, DstEnd RangeEnd, 1
from Dst
order by RangeStart; |
create table #year
(
YearNbr int not null,
DstStart datetime null,
DstEnd datetime null
);
with l0 as (select 1 v union all select 1), l1 as (select a.v from l0 a, l0), l2 as (select a.v from l1 a, l1),
l3 as (select a.v from l2 a, l2), l4 as (select a.v from l3 a, l3), l5 as (select a.v from l4 a, l4),
nums as (select row_number() over (order by (select null)) n from l5)
insert #year (YearNbr)
select n.n
from nums n
where n.n >= 1966
and n.n <= 2099;
update y
set y.DstStart = dst.dst_begin,
y.DstEnd = dst.dst_end
from #year y cross apply (select * from fn_GetDSTBeginEnd(datefromparts(y.YearNbr, 1, 1))) dst;
with Dst as
(
select y.YearNbr,
lag(y.DstEnd, 1, null) over (order by y.YearNbr) PrevDstEnd,
y.DstStart,
y.DstEnd
from #year y
)
insert DstRanges (RangeStart, RangeEnd, IsDst)
select Dst.PrevDstEnd RangeStart, DstStart RangeEnd, 0
from Dst
union all
select DstStart RangeStart, DstEnd RangeEnd, 1
from Dst
order by RangeStart;
Finally, we define a pair of table-valued functions (one helper function, and one intended to be called by the user). Be sure to change the name of your Admin database in the two places it is referenced (lines 11 and 27).
if exists (select * from sys.objects where name = 'fn_GetDSTInfo')
drop function fn_GetDSTInfo
go
create function fn_GetDSTInfo (@TargetDate datetime2)
returns table
as
return
select td.TargetDate,
isnull(r.IsDst, 0) IsDst
from (select @TargetDate TargetDate) td
left join Admin.dbo.DstRanges r
on r.RangeStart <= td.TargetDate
and r.RangeEnd > td.TargetDate;
go
if exists (select * from sys.objects where name = 'fn_LocalTimeToUTC')
drop function fn_LocalTimeToUTC;
go
create function fn_LocalTimeToUTC (@LocalTime datetime2, @UtcOffsetHours int, @UsesDst bit)
returns table
as
return
with OffsetInfo as
(
select @LocalTime LocalTime,
@UtcOffsetHours UtcOffsetHours,
case when @UsesDst = 1 and dst.IsDst = 1 then 1 else 0 end DstOffsetHours
from Admin.dbo.fn_GetDSTInfo(@LocalTime) dst
)
select OffsetInfo.LocalTime,
OffsetInfo.UtcOffsetHours,
OffsetInfo.DstOffsetHours,
dateadd(hour, -(OffsetInfo.UtcOffsetHours + OffsetInfo.DstOffsetHours), OffsetInfo.LocalTime) UtcTime
from OffsetInfo;
go |
if exists (select * from sys.objects where name = 'fn_GetDSTInfo')
drop function fn_GetDSTInfo
go
create function fn_GetDSTInfo (@TargetDate datetime2)
returns table
as
return
select td.TargetDate,
isnull(r.IsDst, 0) IsDst
from (select @TargetDate TargetDate) td
left join Admin.dbo.DstRanges r
on r.RangeStart <= td.TargetDate
and r.RangeEnd > td.TargetDate;
go
if exists (select * from sys.objects where name = 'fn_LocalTimeToUTC')
drop function fn_LocalTimeToUTC;
go
create function fn_LocalTimeToUTC (@LocalTime datetime2, @UtcOffsetHours int, @UsesDst bit)
returns table
as
return
with OffsetInfo as
(
select @LocalTime LocalTime,
@UtcOffsetHours UtcOffsetHours,
case when @UsesDst = 1 and dst.IsDst = 1 then 1 else 0 end DstOffsetHours
from Admin.dbo.fn_GetDSTInfo(@LocalTime) dst
)
select OffsetInfo.LocalTime,
OffsetInfo.UtcOffsetHours,
OffsetInfo.DstOffsetHours,
dateadd(hour, -(OffsetInfo.UtcOffsetHours + OffsetInfo.DstOffsetHours), OffsetInfo.LocalTime) UtcTime
from OffsetInfo;
go
To use this, we call the fn_LocalTimeToUTC function. It has three parameters.
The local time, expressed as a datetime2
The offset of local time (ignoring daylight saving) from UTC
A bit indicating if daylight saving time is observed locally
For example, I am in the Central Time Zone (-6 hours from UTC) and daylight saving is observed, so I would call:
select * from fn_LocalTimeToUTC(sysdatetime(), -6, 1); |
select * from fn_LocalTimeToUTC(sysdatetime(), -6, 1);
And the output is:

Note that there is ambiguity between 1:00 am and 2:00 am when DST ends in the fall, and there is no good way to resolve that ambiguity. This code presumes that DST is still in effect.
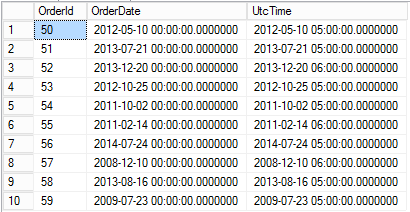
Because fn_LocalTimeToUTC is written as a TVF, it can be efficiently used in set-based operations, usually using an OUTER APPLY operator. For example:
select oh.OrderId, oh.OrderDate, utc.UtcTime
from OrderHeader oh
outer apply Admin.dbo.fn_LocalTimeToUTC(oh.OrderDate, -6, 1) utc
where oh.OrderId >= 50
and oh.OrderId <= 59; |
select oh.OrderId, oh.OrderDate, utc.UtcTime
from OrderHeader oh
outer apply Admin.dbo.fn_LocalTimeToUTC(oh.OrderDate, -6, 1) utc
where oh.OrderId >= 50
and oh.OrderId <= 59;