There are a number of tools out there to create test data, but a few months ago I wanted to try my hand at rolling my own. My initial attempt was a combination of T-SQL and C#, and it works well, but in this blog post I want to demonstrate a pure T-SQL solution. We’ll create random customer data, including first and last names, street address, city and state. This is intended to create addresses that are United States-centric, but the same principles should be applicable anywhere.
Source Data
In order the data to appear realistic, we need to have some basis for creating that data. The U.S. Census Bureau publishes lists of first and last names, and we’ll start with that as a basis. To keep things simple, imagine that there are only 5 last names in the world:
| Name | Frequency |
| Smith | 1.006 |
| Johnson | 0.810 |
| Williams | 0.699 |
| Brown | 0.621 |
| Jones | 0.621 |
We need to “normalize” the frequencies so that they sum to 1. We will also keep a running total on the normalized frequency for all previous rows (there are rounding anomalies in the results).
| Name | Frequency | Normalized Frequency | Running Total |
| Smith | 1.006 | 0.2678 | .0000 |
| Johnson | 0.810 | 0.2156 | .2678 |
| Williams | 0.699 | 0.1861 | .4834 |
| Brown | 0.621 | 0.1653 | .6694 |
| Jones | 0.621 | 0.1653 | .8347 |
Now we can generate a random number from 0 to 1 (more on that in a bit) and use that to select a record in the table. For instance, if the random number is 0.7421, we find the first record where the running total is less than or equal to 0.7421, or “Brown.”
The raw data sources I used were:
Male first names (U.S. Census Bureau)
Female first names (U.S. Census Bureau)
Last names (U.S. Census Bureau)
Cities and states (U.S. Census Bureau)
Street names (I am having a hard time finding where I originally obtained this data. If I figure it out later, I will update this post.)
I have somewhat filtered and modified the data sets, mostly to eliminate frequency information that is rounded to 0 in the raw data. I have also included StreetPrefix and StreetSuffix data sets that I came up with myself.
Let’s create a few tables to store the data:
CREATE TABLE [dbo].[Name]
(
[ID] int NOT NULL IDENTITY(1,1) PRIMARY KEY,
[Name] nvarchar (40) NULL,
[NameType] char (6) NULL,
[Fraction] float NULL
);
CREATE TABLE [dbo].[City]
(
[ID] int NOT NULL IDENTITY(1,1) PRIMARY KEY,
[City] nvarchar (150) NULL,
[State] char (2) NULL,
[Population] int NULL
);
CREATE TABLE [dbo].[StreetPrefix]
(
[ID] int NOT NULL IDENTITY(1,1) PRIMARY KEY,
[Prefix] nvarchar (20) NULL,
[Weight] float NULL
);
CREATE TABLE [dbo].[StreetSuffix]
(
[ID] int NOT NULL IDENTITY(1,1) PRIMARY KEY,
[Suffix] nvarchar (20) NULL,
[Weight] float NULL
);
CREATE TABLE [dbo].[Street]
(
[ID] int NOT NULL IDENTITY(1,1) PRIMARY KEY,
[StreetName] nvarchar (150) NULL
); |
CREATE TABLE [dbo].[Name]
(
[ID] int NOT NULL IDENTITY(1,1) PRIMARY KEY,
[Name] nvarchar (40) NULL,
[NameType] char (6) NULL,
[Fraction] float NULL
);
CREATE TABLE [dbo].[City]
(
[ID] int NOT NULL IDENTITY(1,1) PRIMARY KEY,
[City] nvarchar (150) NULL,
[State] char (2) NULL,
[Population] int NULL
);
CREATE TABLE [dbo].[StreetPrefix]
(
[ID] int NOT NULL IDENTITY(1,1) PRIMARY KEY,
[Prefix] nvarchar (20) NULL,
[Weight] float NULL
);
CREATE TABLE [dbo].[StreetSuffix]
(
[ID] int NOT NULL IDENTITY(1,1) PRIMARY KEY,
[Suffix] nvarchar (20) NULL,
[Weight] float NULL
);
CREATE TABLE [dbo].[Street]
(
[ID] int NOT NULL IDENTITY(1,1) PRIMARY KEY,
[StreetName] nvarchar (150) NULL
);
Note that each of the data sets has some sort of weighting factor except for the Street data. I don’t have any sort of frequency information, so I will just make the assumption that each street is equally likely.
Once the tables are created, download the data file and run it. The data file is a SQL script with a bunch of inserts into the tables. It’s about 200,000 lines long, but it should run fine in SSMS; it just may take a minute or two. Also note that I have combined all of the first and last names into a single table.
Finally, let’s normalize the data sets. It’s easiest to use windowing functions, so this requires at least SQL Server 2012, but with some rewriting it can be done in earlier versions as well. Note that for the names data set we separate out last names from first names (male and female combined). Since the street data does not contain any weighting information, we just use the COUNT function rather than sum. Finally, we’ll create some useful nonclustered indexes.
alter table dbo.Name add NameGroup varchar(10);
update dbo.Name set NameGroup = 'Last' where NameType = 'Last';
update dbo.Name set NameGroup = 'First' where NameType = 'Female';
update dbo.Name set NameGroup = 'First' where NameType = 'Male';
alter table dbo.Name add FractionStart float;
alter table dbo.City add FractionStart float;
alter table dbo.StreetPrefix add FractionStart float;
alter table dbo.StreetSuffix add FractionStart float;
alter table dbo.Street add FractionStart float;
with NameData as
(
select FractionStart,
1.0 * isnull(sum(Fraction) over (partition by NameGroup order by (select null) rows between unbounded preceding and 1 preceding), 0) / sum(Fraction) over (partition by NameGroup) NewFractionStart
from dbo.Name
)
update NameData
set FractionStart = NewFractionStart;
with CityData as
(
select FractionStart,
1.0 * isnull(sum(Population) over (order by (select null) rows between unbounded preceding and 1 preceding), 0) / sum(Population) over () NewFractionStart
from dbo.City
)
update CityData
set FractionStart = NewFractionStart;
with PrefixData as
(
select FractionStart,
1.0 * isnull(sum(Weight) over (order by (select null) rows between unbounded preceding and 1 preceding), 0) / sum(Weight) over () NewFractionStart
from dbo.StreetPrefix
)
update PrefixData
set FractionStart = NewFractionStart;
with SuffixData as
(
select FractionStart,
1.0 * isnull(sum(Weight) over (order by (select null) rows between unbounded preceding and 1 preceding), 0) / sum(Weight) over () NewFractionStart
from dbo.StreetSuffix
)
update SuffixData
set FractionStart = NewFractionStart;
with StreetData as
(
select FractionStart,
1.0 * isnull(count(*) over (order by (select null) rows between unbounded preceding and 1 preceding), 0) / count(*) over () NewFractionStart
from dbo.Street
)
update StreetData
set FractionStart = NewFractionStart;
create nonclustered index IX_Name_NormalizedFraction on dbo.Name (NameGroup, FractionStart);
create nonclustered index IX_City_NormalizedFraction on dbo.City (FractionStart);
create nonclustered index IX_StreetPrefix_NormalizedFraction on dbo.StreetPrefix (FractionStart);
create nonclustered index IX_StreetSuffix_NormalizedFraction on dbo.StreetSuffix (FractionStart);
create nonclustered index IX_Street_NormalizedFraction on dbo.Street (FractionStart); |
alter table dbo.Name add NameGroup varchar(10);
update dbo.Name set NameGroup = 'Last' where NameType = 'Last';
update dbo.Name set NameGroup = 'First' where NameType = 'Female';
update dbo.Name set NameGroup = 'First' where NameType = 'Male';
alter table dbo.Name add FractionStart float;
alter table dbo.City add FractionStart float;
alter table dbo.StreetPrefix add FractionStart float;
alter table dbo.StreetSuffix add FractionStart float;
alter table dbo.Street add FractionStart float;
with NameData as
(
select FractionStart,
1.0 * isnull(sum(Fraction) over (partition by NameGroup order by (select null) rows between unbounded preceding and 1 preceding), 0) / sum(Fraction) over (partition by NameGroup) NewFractionStart
from dbo.Name
)
update NameData
set FractionStart = NewFractionStart;
with CityData as
(
select FractionStart,
1.0 * isnull(sum(Population) over (order by (select null) rows between unbounded preceding and 1 preceding), 0) / sum(Population) over () NewFractionStart
from dbo.City
)
update CityData
set FractionStart = NewFractionStart;
with PrefixData as
(
select FractionStart,
1.0 * isnull(sum(Weight) over (order by (select null) rows between unbounded preceding and 1 preceding), 0) / sum(Weight) over () NewFractionStart
from dbo.StreetPrefix
)
update PrefixData
set FractionStart = NewFractionStart;
with SuffixData as
(
select FractionStart,
1.0 * isnull(sum(Weight) over (order by (select null) rows between unbounded preceding and 1 preceding), 0) / sum(Weight) over () NewFractionStart
from dbo.StreetSuffix
)
update SuffixData
set FractionStart = NewFractionStart;
with StreetData as
(
select FractionStart,
1.0 * isnull(count(*) over (order by (select null) rows between unbounded preceding and 1 preceding), 0) / count(*) over () NewFractionStart
from dbo.Street
)
update StreetData
set FractionStart = NewFractionStart;
create nonclustered index IX_Name_NormalizedFraction on dbo.Name (NameGroup, FractionStart);
create nonclustered index IX_City_NormalizedFraction on dbo.City (FractionStart);
create nonclustered index IX_StreetPrefix_NormalizedFraction on dbo.StreetPrefix (FractionStart);
create nonclustered index IX_StreetSuffix_NormalizedFraction on dbo.StreetSuffix (FractionStart);
create nonclustered index IX_Street_NormalizedFraction on dbo.Street (FractionStart);
Now that we have data, let’s take a look at the idea of randomness.
Randomness
Unfortunately, the built-in SQL Server rand() function has a lot of limitations, not the least of which is that the function returns the same value when called in set-based operations. For instance, try running
select ID, Suffix, Weight, FractionStart, rand() RandValue from StreetSuffix; |
select ID, Suffix, Weight, FractionStart, rand() RandValue from StreetSuffix;
You’ll get a different value for the RandValue column every time you run this statement, but the you’ll also get the same value in each row. This makes rand() OK for row-by-row operations, but fairly useless in the set-based world.
Fortunately, the newid() function comes to the rescue. For example, consider
select ID, Suffix, Weight, FractionStart, newid() RandGuid from StreetSuffix; |
select ID, Suffix, Weight, FractionStart, newid() RandGuid from StreetSuffix;
Every time you run this, you will get a different GUID in each row. To turn this into a random number, we can compute the binary_checksum() of the GUID. Since binary_checksum() returns a value in the range of int, we can normalize the random value by adding a number to it to ensure the result is non-negative and then dividing by the range of int values.
select ID, Suffix, Weight, FractionStart,
(binary_checksum(newid()) + 2147483648.) / 4294967296. RandValue
from StreetSuffix; |
select ID, Suffix, Weight, FractionStart,
(binary_checksum(newid()) + 2147483648.) / 4294967296. RandValue
from StreetSuffix;
It’s ugly, but we now get a random value that is greater than or equal to zero and less than one.
Now we can generate a random city:
select top 1 City, State
from dbo.City
where FractionStart <= (binary_checksum(newid()) + 2147483648.) / 4294967296.
order by FractionStart desc; |
select top 1 City, State
from dbo.City
where FractionStart <= (binary_checksum(newid()) + 2147483648.) / 4294967296.
order by FractionStart desc;
If you execute this statement a number of times, you find that it tends to favor larger cities. This is exactly what we expect. All other things being equal, realistic data will show far more customer from Los Angelos, CA than from a small midwestern town.
Random Values over Ranges of Data
So far, we’ve covered how to select a random item out of a finite list of data, but what about generating random values over ranges. In our situation, we need to create a house number as part of the address. My initial arbitrary rules were:
- The house number should contain between 1 and 5 digits. The specific number of digits is randomly determined.
- If the house number has 5 digits, the first digit should be 1. (This is to avoid fairly unrealistic addresses such as 87369 Main St.)
- There should be no leading zeros in the house number.
We can generate a single random digit from 0 to 9 with this statement:
select cast((binary_checksum(newid()) + 2147483648.) / 4294967296. * 10. as int); |
select cast((binary_checksum(newid()) + 2147483648.) / 4294967296. * 10. as int);
Now, we could string together some code to follows the above rules exactly, but what they really come down is that we need a number from 1 to 19,999:
select 1 + cast((binary_checksum(newid()) + 2147483648.) / 4294967296. * 19999. as int); |
select 1 + cast((binary_checksum(newid()) + 2147483648.) / 4294967296. * 19999. as int);
Certainly a case could be made that house numbers will tend toward smaller values (and even better, could be correlated with the size of the associated city) but we’ll keep things simple here and stick with this simple requirement.
Putting It Together
Now we have the data that we need, as well as a means to produce data randomly. Using the same strategy that we used before to get a random city, we can get all the different bits of pieces of the customer record:
with FirstName as
(
select top 1 Name FirstName
from dbo.Name
where NameGroup = 'First'
and FractionStart <= (binary_checksum(newid()) + 2147483648.) / 4294967296.
order by NameGroup, FractionStart desc
), LastName as
(
select top 1 Name LastName
from dbo.Name
where NameGroup = 'Last'
and FractionStart <= (binary_checksum(newid()) + 2147483648.) / 4294967296.
order by FractionStart desc
), HouseNumber as
(
select 1 + cast((binary_checksum(newid()) + 2147483648.) / 4294967296. * 19999. as int) HouseNumber
), StreetPrefix as
(
select top 1 Prefix
from dbo.StreetPrefix
where FractionStart <= (binary_checksum(newid()) + 2147483648.) / 4294967296.
order by FractionStart desc
), StreetName as
(
select top 1 StreetName
from dbo.Street
where FractionStart <= (binary_checksum(newid()) + 2147483648.) / 4294967296.
order by FractionStart desc
), StreetSuffix as
(
select top 1 Suffix
from dbo.StreetSuffix
where FractionStart <= (binary_checksum(newid()) + 2147483648.) / 4294967296.
order by FractionStart desc
), CityState as
(
select top 1 City, State
from dbo.City
where FractionStart <= (binary_checksum(newid()) + 2147483648.) / 4294967296.
order by FractionStart desc
), RandomCustomer as
(
select FirstName.FirstName,
LastName.LastName,
cast(HouseNumber.HouseNumber as varchar(5)) + ' ' + StreetPrefix.Prefix + ' ' + StreetName.StreetName + ' ' + StreetSuffix.Suffix Address,
CityState.City,
CityState.State
from FirstName, LastName, HouseNumber, StreetPrefix, StreetName, StreetSuffix, CityState
)
select *
from RandomCustomer; |
with FirstName as
(
select top 1 Name FirstName
from dbo.Name
where NameGroup = 'First'
and FractionStart <= (binary_checksum(newid()) + 2147483648.) / 4294967296.
order by NameGroup, FractionStart desc
), LastName as
(
select top 1 Name LastName
from dbo.Name
where NameGroup = 'Last'
and FractionStart <= (binary_checksum(newid()) + 2147483648.) / 4294967296.
order by FractionStart desc
), HouseNumber as
(
select 1 + cast((binary_checksum(newid()) + 2147483648.) / 4294967296. * 19999. as int) HouseNumber
), StreetPrefix as
(
select top 1 Prefix
from dbo.StreetPrefix
where FractionStart <= (binary_checksum(newid()) + 2147483648.) / 4294967296.
order by FractionStart desc
), StreetName as
(
select top 1 StreetName
from dbo.Street
where FractionStart <= (binary_checksum(newid()) + 2147483648.) / 4294967296.
order by FractionStart desc
), StreetSuffix as
(
select top 1 Suffix
from dbo.StreetSuffix
where FractionStart <= (binary_checksum(newid()) + 2147483648.) / 4294967296.
order by FractionStart desc
), CityState as
(
select top 1 City, State
from dbo.City
where FractionStart <= (binary_checksum(newid()) + 2147483648.) / 4294967296.
order by FractionStart desc
), RandomCustomer as
(
select FirstName.FirstName,
LastName.LastName,
cast(HouseNumber.HouseNumber as varchar(5)) + ' ' + StreetPrefix.Prefix + ' ' + StreetName.StreetName + ' ' + StreetSuffix.Suffix Address,
CityState.City,
CityState.State
from FirstName, LastName, HouseNumber, StreetPrefix, StreetName, StreetSuffix, CityState
)
select *
from RandomCustomer;
It would be nice if we could generate multiple customers at once, but here we run into some trouble. If we try joining the above to a tally table, we might hope that we get a whole bunch of customers. But, alas, the optimizer outsmarts us and all we get is repeated rows (well, mostly repeated; the house number does in fact change from row to row, but otherwise it’s all the same output). Nor can we wrap the above statement into a table-valued function because the newid() function is not allowed.
There is a solution, however. It’s a bit clunky, but it does work. Let’s create a TVF where the random values are passed in as parameters:
if exists (select * from sys.objects where name = 'fnGenerateRandomCustomer' and type = 'IF')
drop function fnGenerateRandomCustomer;
go
create function fnGenerateRandomCustomer(@r1 float, @r2 float, @r3 float, @r4 float, @r5 float, @r6 float, @r7 float)
returns table
as
return
with FirstName as
(
select top 1 Name FirstName
from dbo.Name
where NameGroup = 'First'
and FractionStart <= @r1
order by NameGroup, FractionStart desc
), LastName as
(
select top 1 Name LastName
from dbo.Name
where NameGroup = 'Last'
and FractionStart <= @r2
order by FractionStart desc
), HouseNumber as
(
select 1 + cast(@r3 * 19999. as int) HouseNumber
), StreetPrefix as
(
select top 1 Prefix
from dbo.StreetPrefix
where FractionStart <= @r4
order by FractionStart desc
), StreetName as
(
select top 1 StreetName
from dbo.Street
where FractionStart <= @r5
order by FractionStart desc
), StreetSuffix as
(
select top 1 Suffix
from dbo.StreetSuffix
where FractionStart <= @r6
order by FractionStart desc
), CityState as
(
select top 1 City, State
from dbo.City
where FractionStart <= @r7
order by FractionStart desc
), RandomCustomer as
(
select FirstName.FirstName,
LastName.LastName,
cast(HouseNumber.HouseNumber as varchar(5)) + ' ' + StreetPrefix.Prefix + ' ' + StreetName.StreetName + ' ' + StreetSuffix.Suffix Address,
CityState.City,
CityState.State
from FirstName, LastName, HouseNumber, StreetPrefix, StreetName, StreetSuffix, CityState
)
select *
from RandomCustomer; |
if exists (select * from sys.objects where name = 'fnGenerateRandomCustomer' and type = 'IF')
drop function fnGenerateRandomCustomer;
go
create function fnGenerateRandomCustomer(@r1 float, @r2 float, @r3 float, @r4 float, @r5 float, @r6 float, @r7 float)
returns table
as
return
with FirstName as
(
select top 1 Name FirstName
from dbo.Name
where NameGroup = 'First'
and FractionStart <= @r1
order by NameGroup, FractionStart desc
), LastName as
(
select top 1 Name LastName
from dbo.Name
where NameGroup = 'Last'
and FractionStart <= @r2
order by FractionStart desc
), HouseNumber as
(
select 1 + cast(@r3 * 19999. as int) HouseNumber
), StreetPrefix as
(
select top 1 Prefix
from dbo.StreetPrefix
where FractionStart <= @r4
order by FractionStart desc
), StreetName as
(
select top 1 StreetName
from dbo.Street
where FractionStart <= @r5
order by FractionStart desc
), StreetSuffix as
(
select top 1 Suffix
from dbo.StreetSuffix
where FractionStart <= @r6
order by FractionStart desc
), CityState as
(
select top 1 City, State
from dbo.City
where FractionStart <= @r7
order by FractionStart desc
), RandomCustomer as
(
select FirstName.FirstName,
LastName.LastName,
cast(HouseNumber.HouseNumber as varchar(5)) + ' ' + StreetPrefix.Prefix + ' ' + StreetName.StreetName + ' ' + StreetSuffix.Suffix Address,
CityState.City,
CityState.State
from FirstName, LastName, HouseNumber, StreetPrefix, StreetName, StreetSuffix, CityState
)
select *
from RandomCustomer;
Then we invoke the function by generating the random values and passing them to the function. We’ll generate a virtual Nums table to control the number of customers produced, and then generate seven random numbers to be passed to the TVF we just created.
declare @customersToGenerate int = 10;
with l0 as (select 1 v union all select 1), l1 as (select a.v from l0 a, l0), l2 as (select a.v from l1 a, l1),
l3 as (select a.v from l2 a, l2), l4 as (select a.v from l3 a, l3), l5 as (select a.v from l4 a, l4),
Nums as (select row_number() over (order by (select null)) n from l5),
RandomValues as
(
select (binary_checksum(newid()) + 2147483648.) / 4294967296. r1,
(binary_checksum(newid()) + 2147483648.) / 4294967296. r2,
(binary_checksum(newid()) + 2147483648.) / 4294967296. r3,
(binary_checksum(newid()) + 2147483648.) / 4294967296. r4,
(binary_checksum(newid()) + 2147483648.) / 4294967296. r5,
(binary_checksum(newid()) + 2147483648.) / 4294967296. r6,
(binary_checksum(newid()) + 2147483648.) / 4294967296. r7
from Nums n
where n.n <= @customersToGenerate
)
select cust.FirstName, cust.LastName, cust.Address, cust.City, cust.State
from RandomValues
cross apply dbo.fnGenerateRandomCustomer(r1, r2, r3, r4, r5, r6, r7) cust; |
declare @customersToGenerate int = 10;
with l0 as (select 1 v union all select 1), l1 as (select a.v from l0 a, l0), l2 as (select a.v from l1 a, l1),
l3 as (select a.v from l2 a, l2), l4 as (select a.v from l3 a, l3), l5 as (select a.v from l4 a, l4),
Nums as (select row_number() over (order by (select null)) n from l5),
RandomValues as
(
select (binary_checksum(newid()) + 2147483648.) / 4294967296. r1,
(binary_checksum(newid()) + 2147483648.) / 4294967296. r2,
(binary_checksum(newid()) + 2147483648.) / 4294967296. r3,
(binary_checksum(newid()) + 2147483648.) / 4294967296. r4,
(binary_checksum(newid()) + 2147483648.) / 4294967296. r5,
(binary_checksum(newid()) + 2147483648.) / 4294967296. r6,
(binary_checksum(newid()) + 2147483648.) / 4294967296. r7
from Nums n
where n.n <= @customersToGenerate
)
select cust.FirstName, cust.LastName, cust.Address, cust.City, cust.State
from RandomValues
cross apply dbo.fnGenerateRandomCustomer(r1, r2, r3, r4, r5, r6, r7) cust;
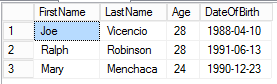
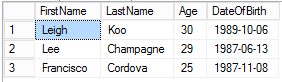
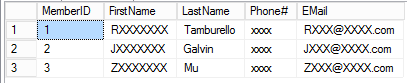
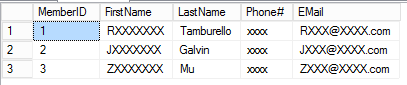
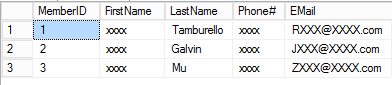
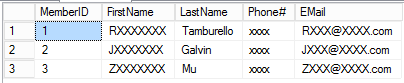
Here is the output from running this script. As you would expect, the results are going to be different every time.
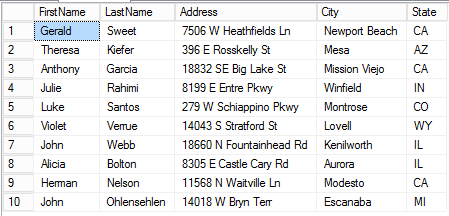
If you look at the actual query plan, you can see that the system is doing an index seek and key lookup on each of the data tables for each customer generated, which is not surprising given the random nature of the query. This means that as the number of customers generated increases, there is a lot overhead doing those key lookups. However, it is still reasonably efficient. On my machine I was able to insert 1,000,000 randomly generated customers into a table in about 30 seconds.
Summary
I have put together this post merely to present an example of how randomized test data can be generated. The focus has been on generating customer names and addresses, but the same principles can be applied to creating a wide variety of data types. It’s not perfect, but it can suffice nicely for a lot of situations.