In the previous post in this series, I introduced the goal of finding missed scheduled jobs in SQL Server. The next step in the solution required what essentially amounted to a custom aggregate in SSIS. This just wasn’t something I’d had to deal with before, so I’ll address that part of the problem in this post.
To keep things simple, I will use an example that is decoupled from the problem at hand. In part 3 of this series, I will use these techniques to present the final missed schedules solution.
My contrived example here is to do a string concatenation aggregate on a customer table where I want all of my customers who live in the same city to be aggregated into the same record. My source query is:
select c.City, c.FirstName + ' ' + c.LastName Name from dbo.Customer c where c.State = 'KS' order by c.City, c.LastName, c.FirstName; |
The first few records from this query are:

Since we have only one customer in Abilene, I would expect for my output to contain a record with just one name for that city.
Abilene | Joe Wolf
Since there are multiple customers in Andover, the output should have this record:
Andover | Clara Anderson, Shirley Holt, Wanda Kemp, Brandon Rowe, Sandra Wilson
Here is how I do the aggregate. I start by creating a data flow task with three components.
In the Source component, I connect to my database and give it the SQL listed above.
Next, I add a Script Component. SSIS prompts me to select the type of script component that this object will be:
This will be a transformation script. After I connect my source to the script component and open the script component, I get this dialog.
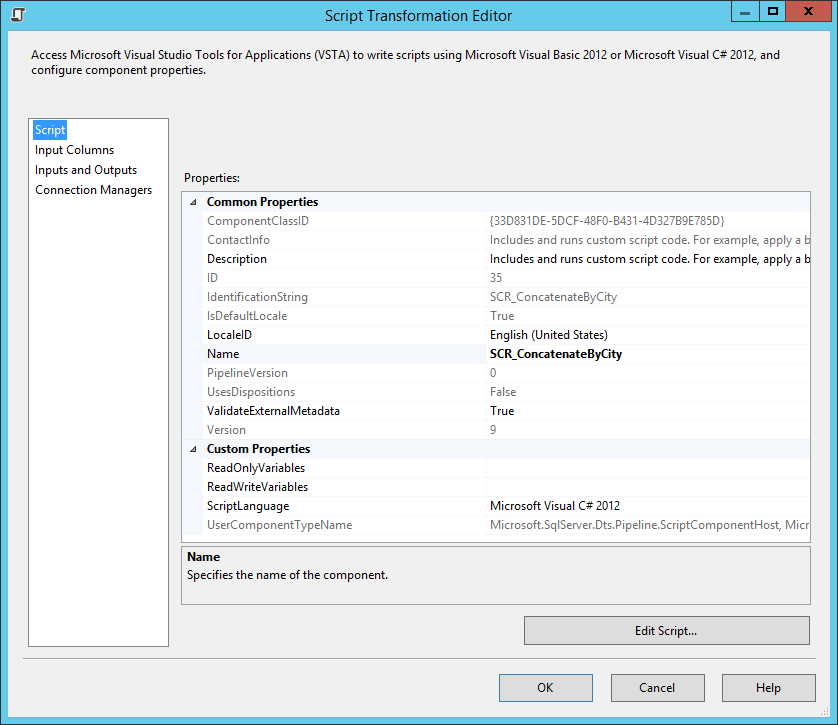
On the Input Columns tab, I make sure that both City and Name are selected, and then I move to the Inputs and Outputs tab. I click on “Output 0.” Here is the secret sauce: I change the SynchronousInputId property to None. The default is that SSIS will have one output row per input row, but making this change allows me to control when an output row is generated. Finally, I expand “Output 0” and click on “Output Columns.” I press the Add Column button, rename it to City, and set the DataType property to “string [DT_STR].” The default length of 50 is OK for this situation. I then add another column, call it “CustomerNames” and make it a string as well and set the length to 8000.
I then go back to the Script tab and edit the script. I replace the Input0_ProcessInputRow method with the following.
public override void Input0_ProcessInputRow(Input0Buffer Row) { string currentCity = Row.City_IsNull ? null : Row.City; if (currentCity == _previousCity) { if (_customers != null) { _customers += ", "; } _customers += Row.Name_IsNull ? string.Empty : Row.Name; } else { if (_customers != null) { Output0Buffer.AddRow(); Output0Buffer.City = _previousCity; Output0Buffer.CustomerNames = _customers; } _customers = Row.Name_IsNull ? string.Empty : Row.Name; } _previousCity = currentCity; } public override void Input0_ProcessInput(Input0Buffer Buffer) { base.Input0_ProcessInput(Buffer); if (Buffer.EndOfRowset()) { if (_customers != null) { Output0Buffer.AddRow(); Output0Buffer.City = _previousCity; Output0Buffer.CustomerNames = _customers; } } } private string _previousCity = null; private string _customers = null; |
What this code does is to take advantage of the fact that our input is sorted by City and reads through the records one at a time, watching for changes to the city field. As it goes, it keeps track of the customers associated with that city, and when the city changes, it writes a records to the output. The code in Input0_ProcessInput exists just to output the final row.
Finally, I create a destination in my data flow task. The destination can be anything we want; I just output to a table.
When I run the package and select from the output table, I get exactly what I expected.

Note that is very similar to how the SQL Stream Aggregate processes data, and it is absolutely dependent on having the input sorted by the aggregation column. If the data is not sorted, we would have to take a very different approach.
In the final part of this post, I will use this same technique to complete the missed jobs monitor.